PCB Inspector
A fully on-device PCB defect inspector running YOLOv8s and a 2B-param LLM on a Raspberry Pi 5.

Project Overview
A factory line operator doesn't want a Jupyter notebook. They want to point a camera at a board, hear "this one's fine" or "open circuit, top right", and move on. So that's what we built.
This was a two-person project with Abir Abidi. We split the work across research, training, and deployment, and shipped the full stack together.
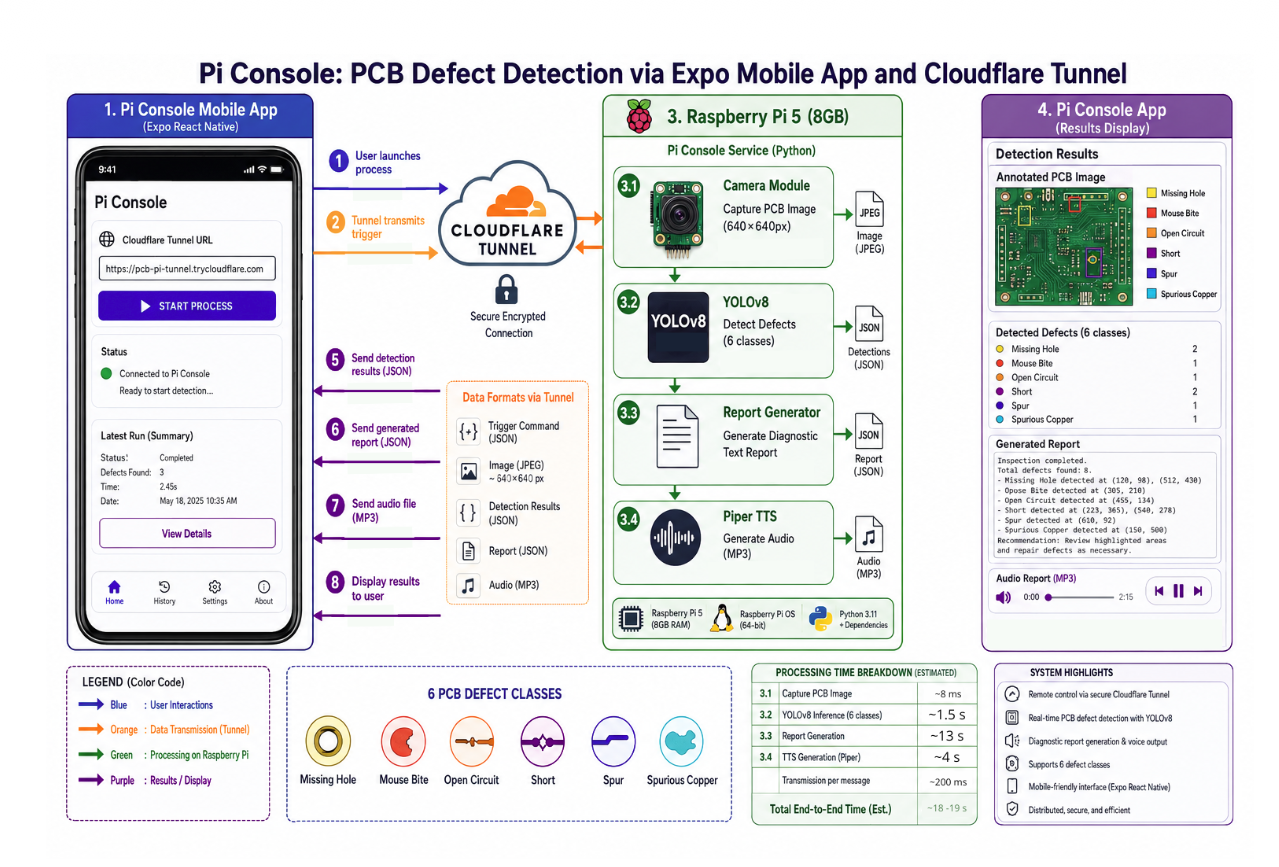
The whole system runs on a Raspberry Pi 5 (8 GB) with a Pi Camera v3. Detection, language model, text-to-speech, and web server all live on the same board. No GPU at inference time, no cloud round-trip, no external API in the loop.
The task is to spot 6 classes of defects on a PCB (missing_hole, mouse_bite, open_circuit, short, spur, spurious_copper) in seconds, and explain the result to a non-technical operator.
Production hardware: Raspberry Pi 5 (8 GB) + Pi Camera Module v3. Training hardware: Azure VM with an NVIDIA T4 (16 GB), AMD EPYC 7V12, 54 GB RAM.
TL;DR
YOLOv8s for perception, Gemma-4-E2B-it (Q4_K_M, ~2B params) for narration, Piper for voice, FastAPI for transport, an Expo app over Cloudflare Tunnel for the operator. mAP@0.5 of 0.953. End-to-end inspection (capture, detect, narrate, speak) in about 21 seconds. Beats a fine-tuned VLM baseline by +91.3 points of exact-match accuracy and +0.83 of macro F1.
The Pipeline
Everything lives on the Pi. The phone is just a remote control with a screen.
Detection Results
YOLOv8s, 3-fold cross-validation on the public PCB defects dataset. 1386 images, 95/5 split, 180 epochs per fold.
| Metric | Value |
|---|---|
| mAP@0.5 | 0.953 |
| mAP@0.5:0.95 | 0.473 |
| Macro Precision | 0.962 |
| Macro Recall | 0.918 |
Per-class F1 stays above 0.85 across all 6 classes. The best class (short) hits 0.996. The hardest one (open_circuit) lands at 0.853, which matches the dataset itself, since open circuits are visually the most ambiguous.
| Class | Precision | Recall | F1 |
|---|---|---|---|
| missing_hole | 0.968 | 1.000 | 0.984 |
| mouse_bite | 0.921 | 0.950 | 0.935 |
| open_circuit | 0.860 | 0.847 | 0.853 |
| short | 0.993 | 1.000 | 0.996 |
| spur | 0.994 | 0.885 | 0.936 |
| spurious_copper | 0.914 | 0.885 | 0.899 |
YOLO vs the VLM Baseline
Before settling on the hybrid pipeline, I evaluated a vision-language model doing the full task end-to-end. Same validation split, same prompt, full multi-label comparison.
| Metric | YOLOv8s | LLaVA-OneVision 0.5B + LoRA |
|---|---|---|
| Exact-match accuracy | 91.3 % | 0.0 % |
| Macro precision | 0.962 | 0.059 |
| Macro recall | 0.918 | 0.167 |
| Macro F1 | 0.939 | 0.043 |
| Mean Jaccard | 0.902 | 0.176 |
The VLM was retired after this run. A 0.5B generalist VLM hallucinated defect classes and never converged on a spatially fine PCB task at that parameter budget.
Edge Performance
Measured during a real inspection session on the Pi 5.
| Stage | Duration | Share |
|---|---|---|
| Photo capture | 5 ms | 0.0 % |
| YOLOv8 inference | 1.71 s | 8.1 % |
| LLM inference (Gemma-4-E2B-it) | 14.44 s | 68.1 % |
| TTS (Piper) | 5.04 s | 23.7 % |
| End-to-end | 21.2 s | 100 % |
- Memory. FastAPI RSS goes from 421 MB to 532 MB peak. System peak sits at 3.64 GB out of 8 GB (43.6 %). The model lives in the
llama-serversubprocess, loaded once at boot and never reloaded. - CPU. 88 to 100 % across all 4 cores during LLM inference. YOLO bursts to 133 % process CPU (about 2 cores).
- Thermal. The SoC climbs from 58 to 75.5 °C and holds, well under the 80 °C soft throttle and the 85 °C hard throttle for a single inspection.
- Network. Cloudflare Tunnel round-trip is 50 to 225 ms, negligible against ~21 s of compute.
What Shipped
- Edge runtime (pcb-inspector-edge). FastAPI service on the Pi exposing
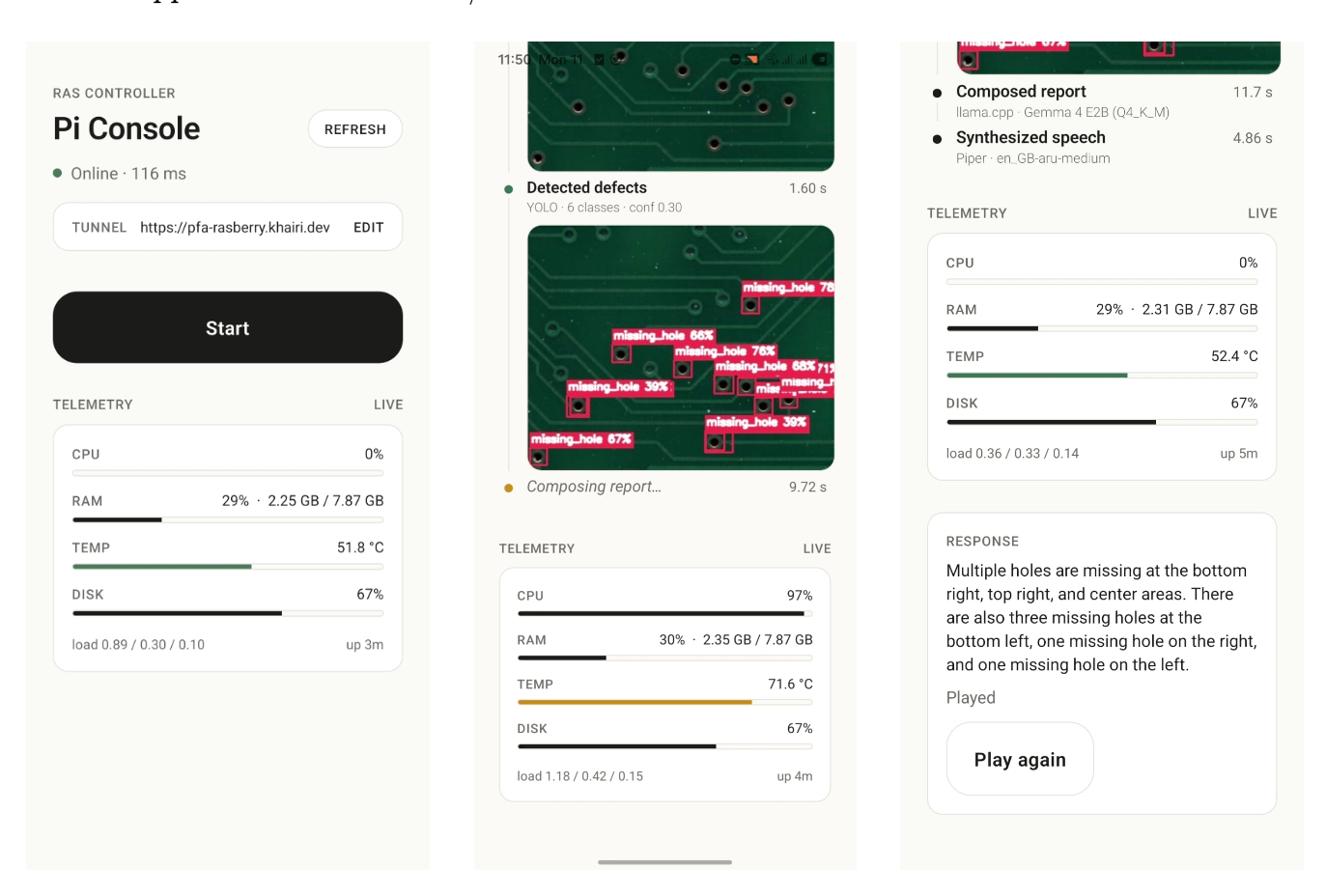
/health,/telemetry, and/ws/start. YOLO, llama-server, and Piper are loaded once during the FastAPI lifespan, so each request only pays inference cost. Annotated frames are served from a static/capturesmount. - Mobile console (pcb-inspector-mobile). Expo / React Native app (iOS 13+, Android 8+) with in-app tunnel URL config, single-tap trigger, streamed milestones, annotated image, generated report, and audio playback. The Pi 5 kit shipped without a physical button and the delivery window was tight, so the app became the operator interface.
- Research repository (pcb-defect-research). Full training pipeline, k-fold cross-validation, YOLO vs VLM comparison, generated PDF report.
- Transport. Cloudflare Tunnel for zero-config secure access from the phone to the Pi, with no port forwarding required.
Engineering Decisions
Decoupling perception from generation
A 0.5B VLM trying to do both perception and language reached only 4.3 % macro F1. YOLOv8s handles the spatially fine detection it was designed for, and a 2B LLM only has to verbalize the structured detection output. That split is the single biggest reason the system works.
Persistent llama-server
The 2.5 GB GGUF is loaded once at boot and reused over HTTP. This removes a ~10 s cold start per inspection and isolates native crashes from the FastAPI process. If llama-server fails, the API stays up and surfaces the error to the operator instead of bringing the whole service down.
TinyLlama-1.1B to Gemma-4-E2B-it, mid-project
Google released Gemma-4 in April 2026 during development, so I migrated. Cost of the swap: latency went from milliseconds to about 14 s. Gain: complete defect coverage (13/13 vs 10/13 on the same prompt). For a one-shot quality-control loop where the operator is standing next to the board, correct answers are worth the extra latency.
The bottleneck is the LLM, not perception
68 % of every inspection is Gemma generating ~50 tokens on 4 Arm cores. The detector is not the bottleneck. The next optimization pass targets token budget and quantization, not the YOLO graph.
Operator UX over hardware
With no physical trigger button on the Pi kit, the mobile app became the control plane. The tunnel gave it remote reach with no extra infrastructure, which turned a missing button into a remote inspection feature.
Lessons
- A small specialist plus a small generalist beats a small generalist trying to do both, especially under tight VRAM.
- "It runs on a Pi" is a useful forcing function: it surfaces architectural problems early.
- The slowest stage in an edge ML pipeline is rarely the one you assume. Profile before optimizing.
- A companion app can be a reasonable substitute for missing hardware, not just a workaround.